A Guide on Getting Started with Data Governance
Rajat Venkatesh — 2/17/2022 — 3 Min Read

In this guest post, Syed Atif Akhtar provides insights on how an organization can get started on Data Governance. He draws these insights from his experience helping large and small organizations structure their data governance systems.
Data Governance helps organizations improve developer productivity and data quality, compliance, and security. However, many organizations fail to extract value from data governance. This post describes the prerequisites and methodologies to implement a data governance platform.
Prerequisites for a Data Governance implementation
Strategy and Vision
The strategy should clearly articulate the value proposition and goals of data governance. Setting goals and objectives across different timelines help everyone in a team see the value and remain motivated to trust the process.
The strategy has to consider both the tools and the organization. It is insufficient to introduce the right tools without a good thought process. Most organizations that follow a top-down approach often fail due to investing too much money in tools but not considering their suitability within their context. Hence, the right incentive has to be created for everyone in the organization to participate and take ownership of data governance within their area.
The strategy should support decentralization and adopt extensible tools. Each team should be able to add features they see fit and evolve the governance fabric based on their needs.
The strategy should consider the needs of different stakeholders in the data lifecycle, including engineers, scientists, and analysts. It must include relational databases and data warehouses with technologies for data engineering, data science, and artificial intelligence. It should also consider that new technologies can eventually replace existing ones, for which engineers in the team can prepare.
The strategy should push data governance in phases. The roadmap should consist of incremental improvements rather than overnight change to allow the organization to assimilate the new technologies and processes.
Comprehensive Goals
The goal of data governance is typically limited to compliance, accountability, and audits. However, the value of data governance goes beyond compliance to develop productivity and data quality. For example, developer productivity and data quality lead to greater motivation to choose suitable investments in the future. Goals with data governance are not limited to only the immediate results.
Technology
There are many factors in choosing the right data governance technologies. Some of them are:
- Build versus Buy
- Open-Source versus Commercial
These decisions depend on the organization's goals, vision, and capabilities. For instance, the organization may not be able to install and maintain an open-source project. In other cases, the project may not work with the ecosystem adopted by the enterprise.
Steps to implementing Successful Data Governance
Prototype Phase
The goal of the prototype phase is to answer the following questions:
- What are the datasets available?
- Who is using the datasets?
- How are the datasets used?
In the prototype phase: Curate important data Focus on a few teams, ideally those of Data Science of AI teams Implement basic classification and tagging of data
Enabling Phase
The goal of the enabling phase is to add tooling to analyze metadata and enable compliance
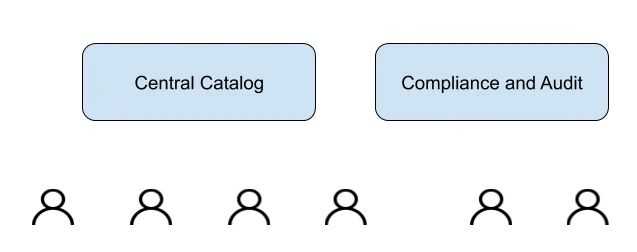
In the enabling phase:
- The organization moves to a push-based model
- There is a focus on reducing the friction to onboard new teams and datasets
- A central team creates compliance and audit policies
- Technology is augmented to analyze and implement these policies
- Automate reporting of compliance reports
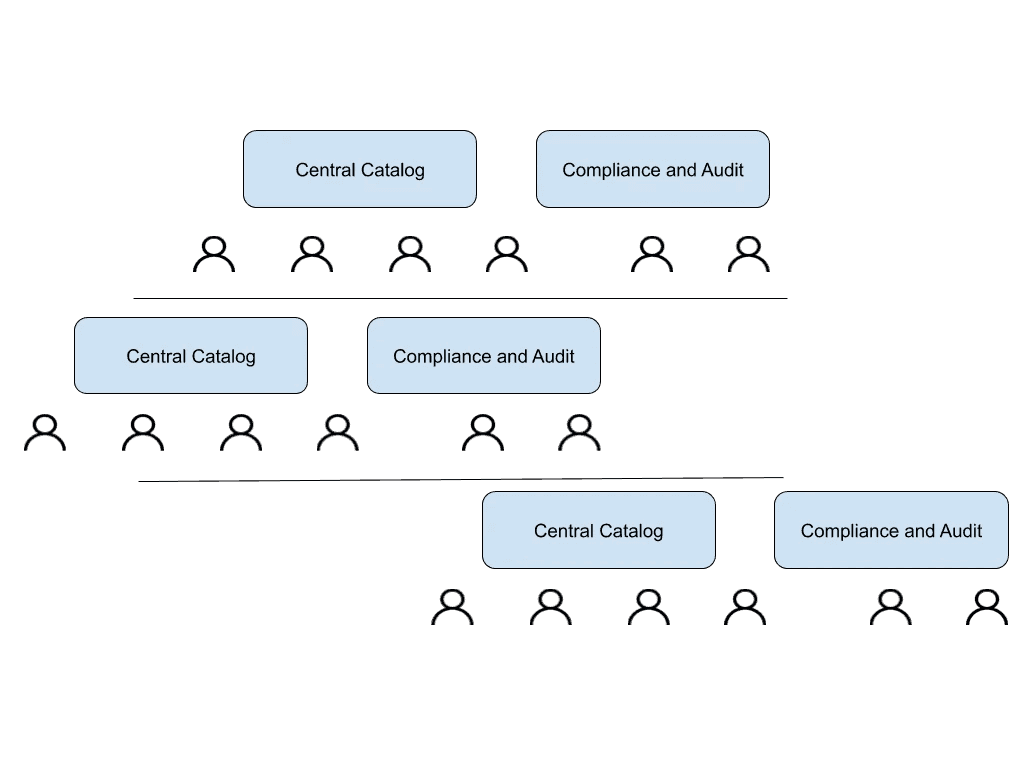
Scaling Phase
In the final phase, the goal is to align teams on data domains and federate data governance.
In the scaling phase:
- Data governance is decentralized. Data stewards are part of sub-organizations.
- Sub-organizations may flexibly choose policies and manage them through an Open Policy Agent.
- Distributed data catalogs reflect the architecture of different data marts.
- A business glossary links code, SQL scripts, models, and transformations across different sub-organizations and data catalogs
Conclusion
This post provides a blueprint for organizations to implement data governance structures and extract value from them. Organizations should focus on strategy, goals, and technology and integrate these in phases by completing tasks step-by-step.
Similar Posts

What are the differences between data catalogs, dictionaries, taxonomies and glossaries?
Rajat Venkatesh — 10/9/2020 - 3 Min Read
Learn which data system you should use, based on who uses the metadata.

Analyze Access Permissions for AWS Glue and Lake Formation
Rajat Venkatesh — 12/9/2019 - 2 Min Read
Analyze your AWS Glue access permissions for managed access to PII, PHI in your data lakes.

Tutorial: How to set up Access Permissions for AWS Lake Formation with Examples
Rajat Venkatesh — 11/26/2019 - 2 Min Read
Learn how to setup AWS Lake Formation permissions to secure your S3 data lakes.
Get in touch for bespoke support for PII Catcher
We can help discover, manage and secure sensitive data in your data warehouse.