Why do we need Data Governance? What are its Challenges?
Rajat Venkatesh — 7/10/2020 — 1 Min Read

The first step is to understand what data governance is. Data Governance is an overloaded term and means different things to different people. It has been helpful to define Data Governance based on the outcomes it is supposed to deliver. In my case, Data Governance is any task required for:
- Compliance: Data life cycle and usage are under laws and regulations.
- Privacy: Protect data as per regulations and user expectations.
- Security: Data & data infrastructure is adequately protected.
Why is Data Governance hard?
Compliance, Privacy, and Security are different approaches to ensure that data collectors and processors do not gain unregulated insights. It is hard to ensure that an adequate data governance framework is in place to meet this goal. An interesting example is the sequence of events leading to the leakage of the taxi cab tipping history of celebrities.
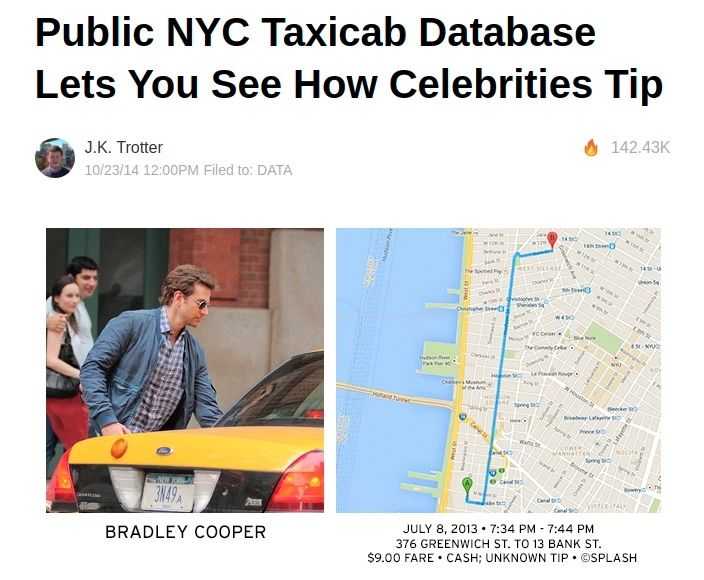
Paparazzi took photos of celebrities in New York City using taxi cabs. These had geo-locations and timestamps along with identifying information about taxi cabs like registration and medallion numbers. Independently, the Taxi Commission released an anonymized dataset of taxi trips with time, medallion numbers, fares, and tips. It was possible to link the metadata from photographs and the taxi usage dataset to determine celebrities' tipping habits. Data Governance is complex because:
- There is too much data
- There is too much complexity in data infrastructure.
- There is no context for data usage.
There is too much data.
Businesses are collecting and sharing more user data than ever before. For example, the image below lists some companies with which PayPal has data-sharing agreements.

As companies share and hoard more data, they may link these datasets to garner insights that were unexpected by the user.
There is too much complexity.

The Data & AI Landscape lists approximately 1500 open-source and commercial technologies. In a small survey, I found that a simple data infrastructure uses 8-10 components. Data and security teams must ensure compliance and security across all parts of the data infrastructure, which is very hard to accomplish.
How to get started on Data Governance?
Analytics, Data Science, and AI objectives compete with compliance, privacy, and security. A blanket “Yes” or “No” access policies do not work. More context is required to enforce access policies appropriately:
- Where is my data?
- Who has access to data?
- How is the data used?
Typically, teams care only about sensitive data. Every company will have a different definition of sensitive data, with Personally Identifiable Information (PII), Protected Health Information (PHI), or financial data most often meeting these definitions. It is also necessary to ensure the process of obtaining answers is automated. Automation will ensure that the data governance framework is relevant and efficient when required.
Where is my sensitive data?
A data catalog, scanner, and data lineage application are required to keep track of sensitive data. An example of a data catalog and scanner is PIICatcher. PIICatcher can scan databases and detect PII data. It can catch other types of sensitive data with some adaptation. The image shows the metadata stored by PIICatcher after a data scan in AWS S3 in the AWS Glue Catalog.
piicatcher aws -r <region> --catalog-format glue
After the run, PIICatcher adds a new parameter with key PII and value as the category of PII. The same table now has the following metadata:
'Columns': [
{
'Name': 'locationid',
'Type': 'bigint'
},
{
'Name': 'borough',
'Type': 'string',
'Parameters': {
'PII': 'PiiTypes.ADDRESS'
}
},
{
'Name': 'zone',
'Type': 'string',
'Parameters': {
'PII': 'PiiTypes.ADDRESS'
}
},
{
'Name': 'service_zone',
'Type': 'string',
'Parameters': {
'PII': 'PiiTypes.ADDRESS'
}
}
]
Rather than scanning all the datasets, it is sufficient to focus on base datasets and then build a data lineage graph to track sensitive data. A library-like data lineage can construct a DAG from query history using a graphing library. The DAG can be used to visualize the graph or process it programmatically.
Who has access to my sensitive data?
Most databases have an information schema that stores the privileges of users and roles. This schema can be "joined" with a data catalog where columns with sensitive data are tagged to get a list of users with access to sensitive data. The query below demonstrates this programmatically:
SELECT DISTINCT `PRINCIPAL` FROM `COLUMNS` INNER JOIN `TABLE_PRIVILEGES` ON
`COLUMNS`.`TABLE_SCHEMA` = `TABLE_PRIVILEGES`.`SCHEMA_NAME` AND
`COLUMNS`.`TABLE_NAME` = `TABLE_PRIVILEGES`.`TABLE_NAME`
WHERE `COLUMNS`.`PII` IS NOT NULL AND
`TABLE_PRIVILEGES`.`PERMISSION` IN ('ALL', 'SELECT')
ORDER BY 1
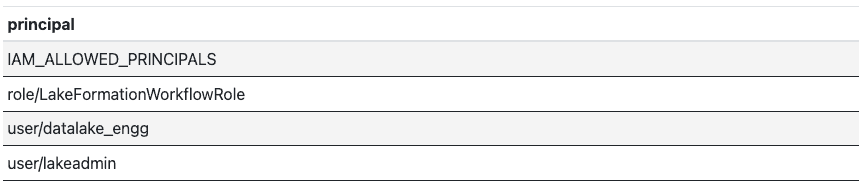
How is sensitive data used?
The first step to determine this is to log usage across all databases, which primarily store query history in the information schema. Big Data technologies like Presto provide hooks to capture usage information. It is not advisable to log usage from production databases. Instead, proxies can log usage and send these statistics to a log aggregator, where it is analyzed.
Conclusion
Data Compliance, Privacy & Security is a journey. Data governance is challenging but can be tackled by starting with simple questions and using automation extensively.
Similar Posts

Open-Source SQL Parsers
Rajat Venkatesh — 10/1/2021 - 3 Min Read
Parsing SQL queries provide superpowers for monitoring data health. This post elaborates on how to get started with parsing SQL for data observability.

Update Release: Column Data Lineage
Rajat Venkatesh — 1/12/2020 - 1 Min Read
An update release for Tokern data-lineage, we now support column level data lineage.

Analyze Access Permissions for AWS Glue and Lake Formation
Rajat Venkatesh — 12/9/2019 - 2 Min Read
Analyze your AWS Glue access permissions for managed access to PII, PHI in your data lakes.
Get in touch for bespoke support for PII Catcher
We can help discover, manage and secure sensitive data in your data warehouse.