Data Lineage on Redshift
Rajat Venkatesh — 1/17/2023 — 3 Min Read

Data Lineage Data Lineage tracks data transformation through all systems. It is important for data governance and security. In Data warehouses and data lakes, a team of data engineers maintains a canonical set of base tables. The source of data of these base tables may be events from the product, logs, or third-party data from SalesForce, Google Analytics, or Segment.
Data analysts and scientists use the base tables for their reports and machine learning algorithms. They may create derived tables to help with their work. It is not uncommon for a data warehouse or lake to have hundreds or thousands of tables. In such a scenario it is important to use automation and visual tools to track data lineage.
This post describes the automated visualization of data lineage in AWS Redshift from query logs of the data warehouse. The techniques are applicable to other technologies as well.
Workload System of Record
A system of record of all database activity is a prerequisite for any analysis. For example, AWS Redshift has many system tables and views that record all the database activity. Since these tables retain data for a limited time, it is necessary to persist the data. AWS provides scripts to store the data in tables within Redshift itself. For performance analysis, the query log stored in STL_QUERY and STL_QUERYTEXT is most important. Tokern reads and processes the records in STL_QUERY & STL_QUERYTEXT at regular intervals. It adds the following information for every query:
- Type of query such as SELECT, DML, DDL, COPY, UNLOAD, etc
- Source tables & columns are read by the query if applicable.
- Source files in S3 for COPY queries.
- Target table & columns where the data was loaded if applicable.
- Target files in S3 for UNLOAD queries.
Data Lineage
Tokern uses the system of record to build a network graph for every table & pipeline. Below is a visualization of infallible_galois:
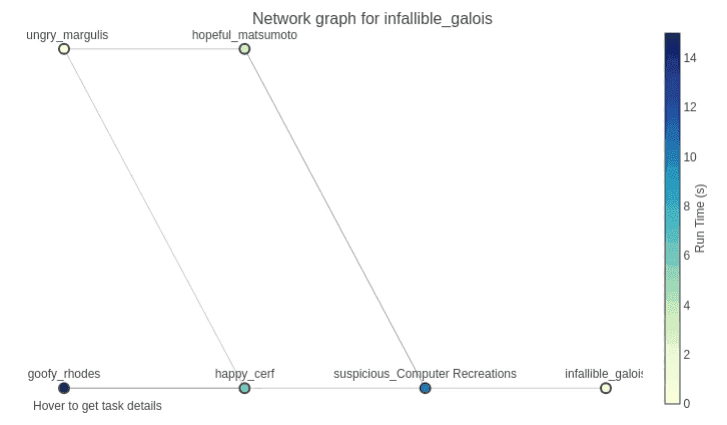
In the network graph, data moves from left to right. Every node (or circle) represents a table. There is an edge (left to right) to a node if the data load reads from that table. A table loads with data from many tables. For example, the data load for hopeful_matsumoto reads data from hungry_margulis. The graph can be analyzed programmatically or used to create interactive charts to help data engineers glean actionable information.
Reduce copies of sensitive data
The security engineers at Company S used a scanning tool to find all tables and columns that stored sensitive data like PII, financial, and business sensitive data. They found that there were many more copies than anticipated. An immediate goal was to reduce the number of copies to reduce the security vulnerability surface area.
Achieving the goal involved:
- Identify the copy owners.
- Understand their motivation for creating copies.
- Work with owners to eliminate copies or use masked copies of the data.
The challenges to achieving these goals were: - Determine the owners of the data.
- The number of conversations required to understand the need for copies and agree on a workaround.
Due to the sheer number of tables, the task was daunting and required an automation tool.
The profile helped the security engineers prepare for the conversation with the owners, with the elimination of duplicate tables on a number of occasions. In other cases, the workflow changes eliminated temporary tables for intermediate data.
In the example below for upbeat_ellis, the workflow eliminated two intermediate tables with sensitive data.
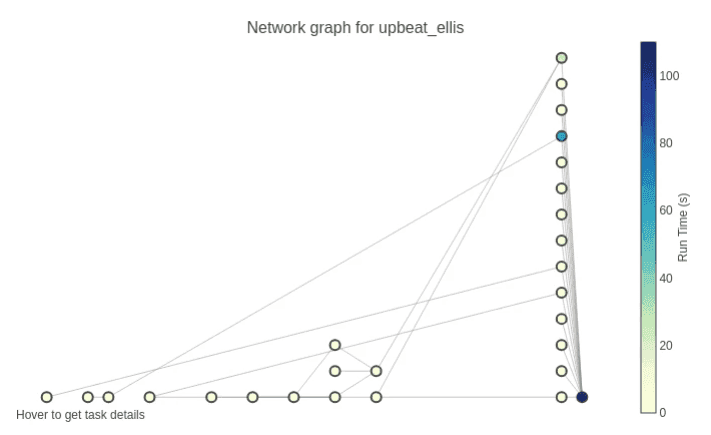
In the network graph, data moves from left to right. Every node (or circle) represents a table. There is an edge (left to right) to a node if the data load reads from that table. A table loads with data from many tables. For example, the data load for hopeful_matsumoto reads data from hungry_margulis. The graph can be analyzed programmatically or used to create interactive charts to help data engineers glean actionable information.
Reduce copies of sensitive data
The security engineers at Company S used a scanning tool to find all tables and columns that stored sensitive data like PII, financial, and business sensitive data. They found that there were many more copies than anticipated. An immediate goal was to reduce the number of copies to reduce the security vulnerability surface area. Achieving the goal involved: Identify the copy owners. Understand their motivation for creating copies. Work with owners to eliminate copies or use masked copies of the data. The challenges to achieving these goals were:
- Determine the owners of the data.
- The number of conversations required to understand the need for copies and agree on a workaround.
Due to the sheer number of tables, the task was daunting and required an automation tool.
Table-specific Network Graphs
Tokern provided the security team with actionable information to discover
- Owners of copies of data
- A profile of the queries used to create the table and read it.
The profile helped the security engineers prepare for the conversation with the owners, with the elimination of duplicate tables on a number of occasions. In other cases, the workflow changes eliminated temporary tables for intermediate data.
In the example below for upbeat_ellis, the workflow eliminated two intermediate tables with sensitive data.
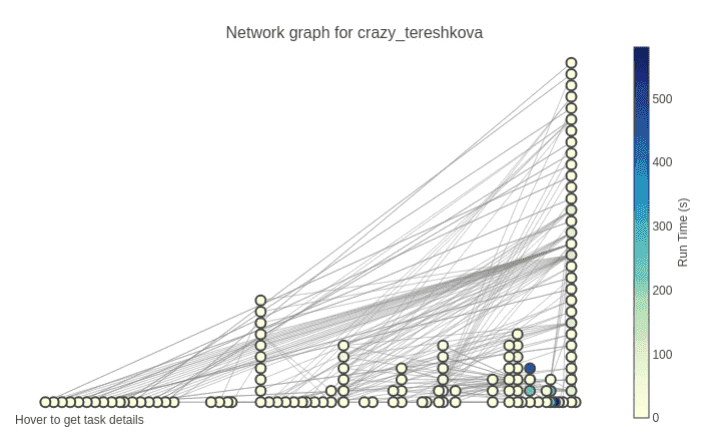
Large Network graphs
Shown below is another example of a network graph for crazy_terseshkova. As seen, the data path is much more complicated, with nearly a hundred tasks required to load data into the table. The interactive graph can be panned & zoomed in to focus on specific parts. To help deal with such complicated data pipelines, hovering over the nodes in the network graph shows metadata such as start time, run time, and table names.
Conclusion
Security Engineers need data lineage and related automation tools to manage database security. All databases provide a workload system of record. Tools such as Tokern Database Security Platform can use this information to visualize data lineage and use rules to automate checks. If this tool interests you, get in touch with us through the chat widget.
Similar Posts

Open-Source SQL Parsers
Rajat Venkatesh — 10/1/2021 - 3 Min Read
Parsing SQL queries provide superpowers for monitoring data health. This post elaborates on how to get started with parsing SQL for data observability.

Why do we need Data Governance? What are its Challenges?
Rajat Venkatesh — 7/10/2020 - 1 Min Read
The first step is to understand what data governance is. Data Governance is an overloaded term and means different things to different people. It has been helpful to define Data Governance based on the outcomes it is supposed to deliver.

Data Lineage on Snowflake
Rajat Venkatesh — 7/1/2020 - 1 Min Read
Use Tokern Data Lineage to visualize data lineage of data in Snowflake.
Get in touch for bespoke support for PII Catcher
We can help discover, manage and secure sensitive data in your data warehouse.