Tutorial: Two Methods to Scan for Personally Identifiable Information (PII) in Data Warehouses
Rajat Venkatesh — 12/1/2021 — 4 Min Read

A vital step towards data privacy and protection is finding and cataloging sensitive PII or PHI data in a data warehouse. Open-source data catalogs like Datahub and Amundsen enable the cataloging of information in warehouses but lack the framework to scan, detect and tag tables or columns that contain such sensitive information.
This post describes two strategies to scan and detect PII, introducing the open-source project PIICatcher, a tool to segregate information stored in a data warehouse.
What is Personally Identifiable Information (PII)?
PII or Personally Identifiable Information is any information that enables the identification of a specific individual. Traditional PII examples include email addresses, social security numbers, personal document IDs, and financial account information. With the evolution of technology, PII now extends to login IDs, IP addresses, geolocation, and biometrics.
PII falls into two types:
- Sensitive: any data that is linked directly to your identity (Credit Card Info, Passport Number, SSN, Legal Name)
- Non-sensitive: any data that can identify an individual and is potentially obtainable from the internet (Address, Ethnicity, IP address)
Compliance laws worldwide have similar definitions of what composes PII:
General Data Protection Regulation (GDPR) (European Union): PII is any data that can help identify an individual. Some examples that have traditionally been considered personally identifiable information include national insurance numbers in the UK, your mailing address, email address, and phone numbers California Consumer Protection Act (CCPA) (United States): The CCPA maintains a broad definition of “personal information” or PI, referring to it as “information that identifies, relates to, describes, is capable of being associated with, or could reasonably be linked, directly or indirectly, with a particular consumer or household.” Other Compliance Laws, including PDPA (Singapore & Thailand), PIPL (China), and CPPA (Canada), refer to PII in similar ways.
Besides these general definitions, businesses may have specific PII data collected for their unique requirements. For instance, firms in the healthcare sector collect Personal Health Information (PHI), whereas bank account or crypto-currency wallet IDs are relevant to the financial sector. Regardless of industry, there is a basic PII that any organization will need to manage:
- Phone
- Credit Card
- Address
- Person/Name
- Location
- Date
- Gender
- Nationality
- IP Address
- SSN
- User Name
- Password
Challenges with scanning for PII
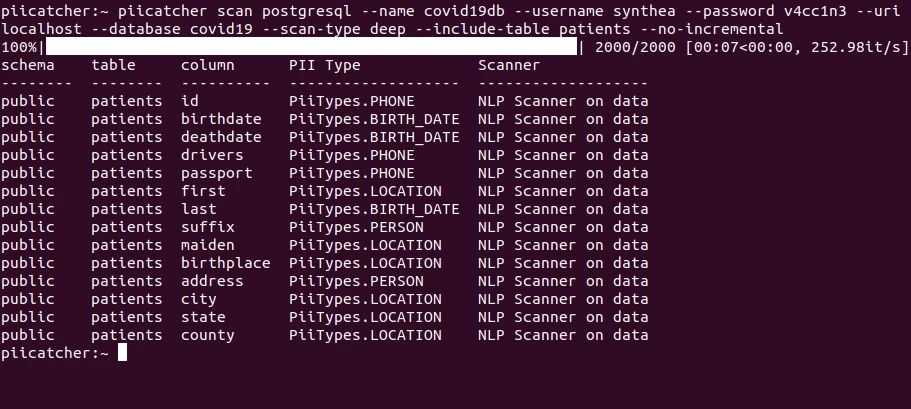
Shown below is an example record in the patients table in Synthetic Patient Records with COVID-19:
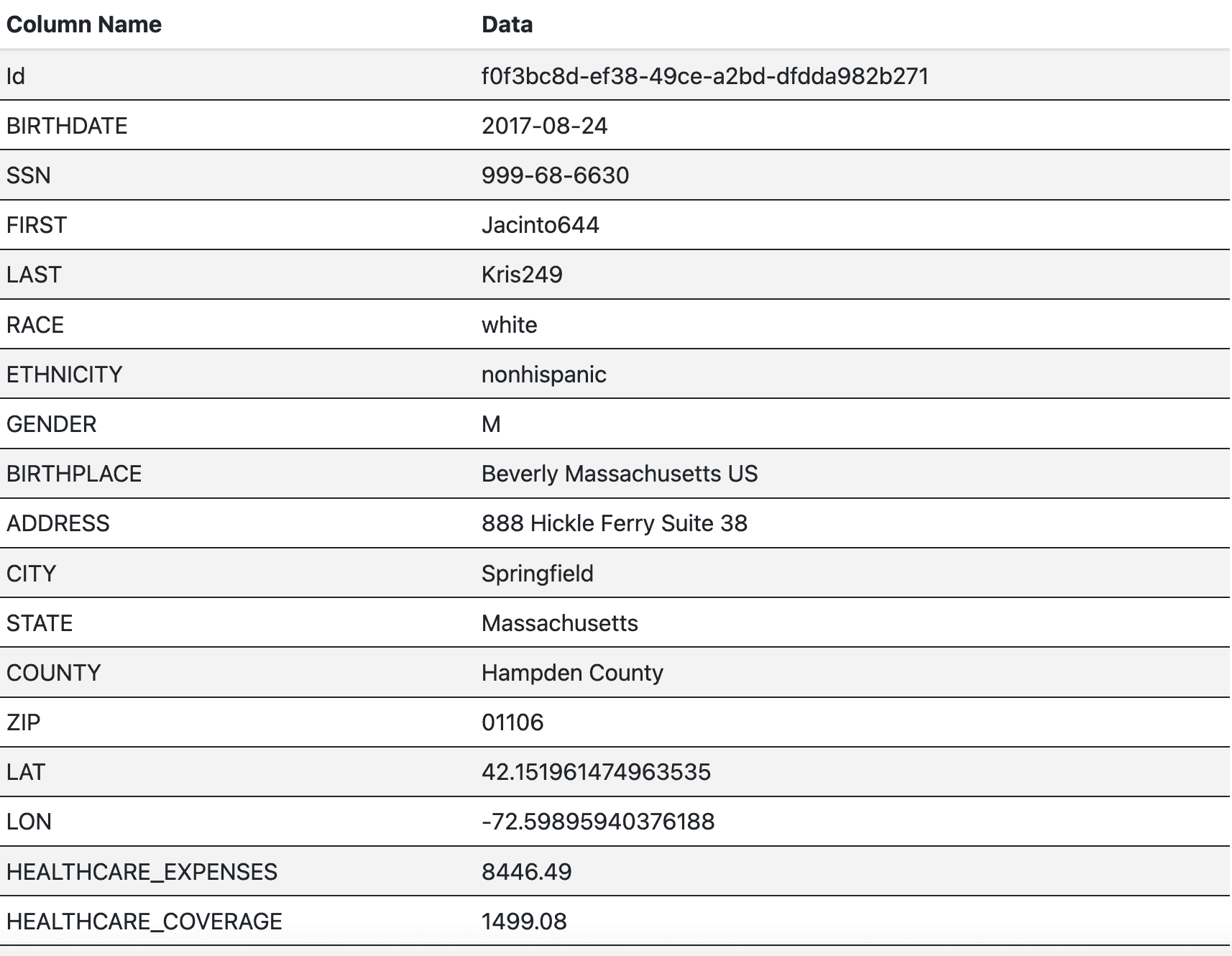
Most of the fields in this table store PII, but it can be confusing to even detect if a column stores PII and if so, the type of that PII. For instance, if the scanner only scans the data in the SSN field, the SSN may be detected as a phone number. Similarly, textual information on its own, such as “M” or “F” in the gender field, or “white” in the race field, does not provide sufficient context to determine the type of PII. In both these cases, it would be more efficient to scan the field headers. However, there are instances where the actual data requires scanning. Therefore, the technique employed to scan a data warehouse is dependent on the context of the field in question.
Techniques to Scan for PII
Based on the challenges highlighted in the previous section, there are two techniques to scan a data warehouse for PII:
- Scan column and table names
- Scan data within columns
Scanning Data Warehouse Metadata (includes column and table names
Often, data engineers name tables and columns in a data warehouse in simple terms that enables ease of understanding for the user. Due to this, these names usually provide clues to the type of data stored. For example:
- first_name, last_name, full_name or name are likely to store the name of a person.
- ssn or social_security are used to store US SSN numbers.
- phone or phone_number are used to store phone numbers.
Furthermore, data warehouses provide an information schema to extract schema, table and column information. For example, the following query can be used to get metadata from Snowflake:
SELECT
lower(c.column_name) AS col_name,
lower(c.column_name) AS col_name,
c.comment AS col_description,
lower(c.data_type) AS col_type,
lower(c.ordinal_position) AS col_sort_order,
lower(c.table_catalog) AS database,
lower({cluster_source}) AS cluster,
lower(c.table_schema) AS schema,
lower(c.table_name) AS name,
t.comment AS description,
decode(lower(t.table_type), 'view', 'true', 'false') AS is_view
FROM
{database}.{schema}.COLUMNS AS c
LEFT JOIN
{database}.{schema}.TABLES t
ON c.TABLE_NAME = t.TABLE_NAME
AND c.TABLE_SCHEMA = t.TABLE_SCHEMA
Regular expressions can match table or column names. For example, the regular expression below detects a column that stores social security numbers:
^.*(ssn|social).*$
Scan Data Stored in Columns
Another method to detect PII involves scanning data stored inside columns using a combination of two strategies:
- Using regular expressions to detect expected patterns
- Calling upon NLP libraries such as Stanford NER Detector and Spacy
One disadvantage of this method is that NLP libraries are computationally intensive. The costs of running NLP scanners on even moderately sized tables rise quickly, let alone millions or billions of rows. Instead, a random sample of rows undergoes the scan. Databases provide built-in functions to choose a random sample, such as the Snowflake query below:
select {column_list} from {schema_name}.{table_name} TABLESAMPLE BERNOULLI (10 ROWS)
Once the random rows are generated, they can be processed with regex or NLP libraries to detect the presence of PII.
Breaking Ties
Both the techniques described above are required to detect PII data, depending on the context. However, these are susceptible to false positives and negatives. Additionally, different approaches can often suggest conflicting PII types. Determining the correct type is a topic for a future blog post.
PIICatcher: Scan data warehouses for PII data
PIICatcher implements the strategies above to scan and detect PII data in data warehouses.
Features
PIICatcher can scan data warehouses using either approach. It is battery-included, with a growing set of regular expressions for scanning column names and the data in those columns. Currently, it even includes Spacy.
PIICatcher supports incremental scans and will only scan new or existing columns awaiting a scan. These features allow for easy scheduling of scans. It also provides powerful options to include or exclude schemas and tables to manage computing resources. Additionally, features for Datahub and Amundsen include ingestion functions that will tag columns and tables with “PII” and “Type of PII” tags.
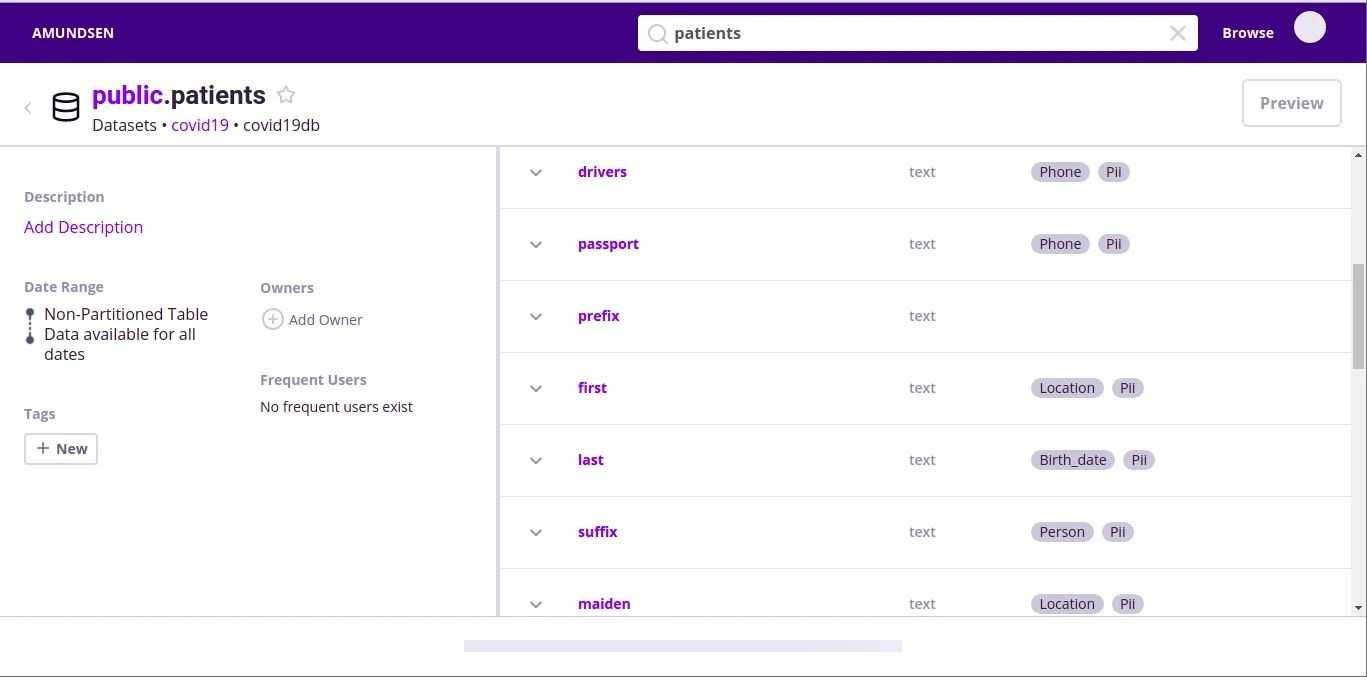
Check out AWS Glue & Lake Formation Privilege Analyzer for an example of PIIcatcher use in production.
Conclusion
Scanning column names and data in tables helps to detect PII in databases. Both strategies are required to detect PII data reliably. PIICatcher is an open-source application that implements both of these strategies. It can tag datasets with PII and the type of PII to enable data admins to make more informed decisions on data privacy and security.
Similar Posts

Open-Source SQL Parsers
Rajat Venkatesh — 10/1/2021 - 3 Min Read
Parsing SQL queries provide superpowers for monitoring data health. This post elaborates on how to get started with parsing SQL for data observability.

Update Release: Column Data Lineage
Rajat Venkatesh — 1/12/2020 - 1 Min Read
An update release for Tokern data-lineage, we now support column level data lineage.

Why do we need Data Governance? What are its Challenges?
Rajat Venkatesh — 7/10/2020 - 1 Min Read
The first step is to understand what data governance is. Data Governance is an overloaded term and means different things to different people. It has been helpful to define Data Governance based on the outcomes it is supposed to deliver.
Get in touch for bespoke support for PII Catcher
We can help discover, manage and secure sensitive data in your data warehouse.