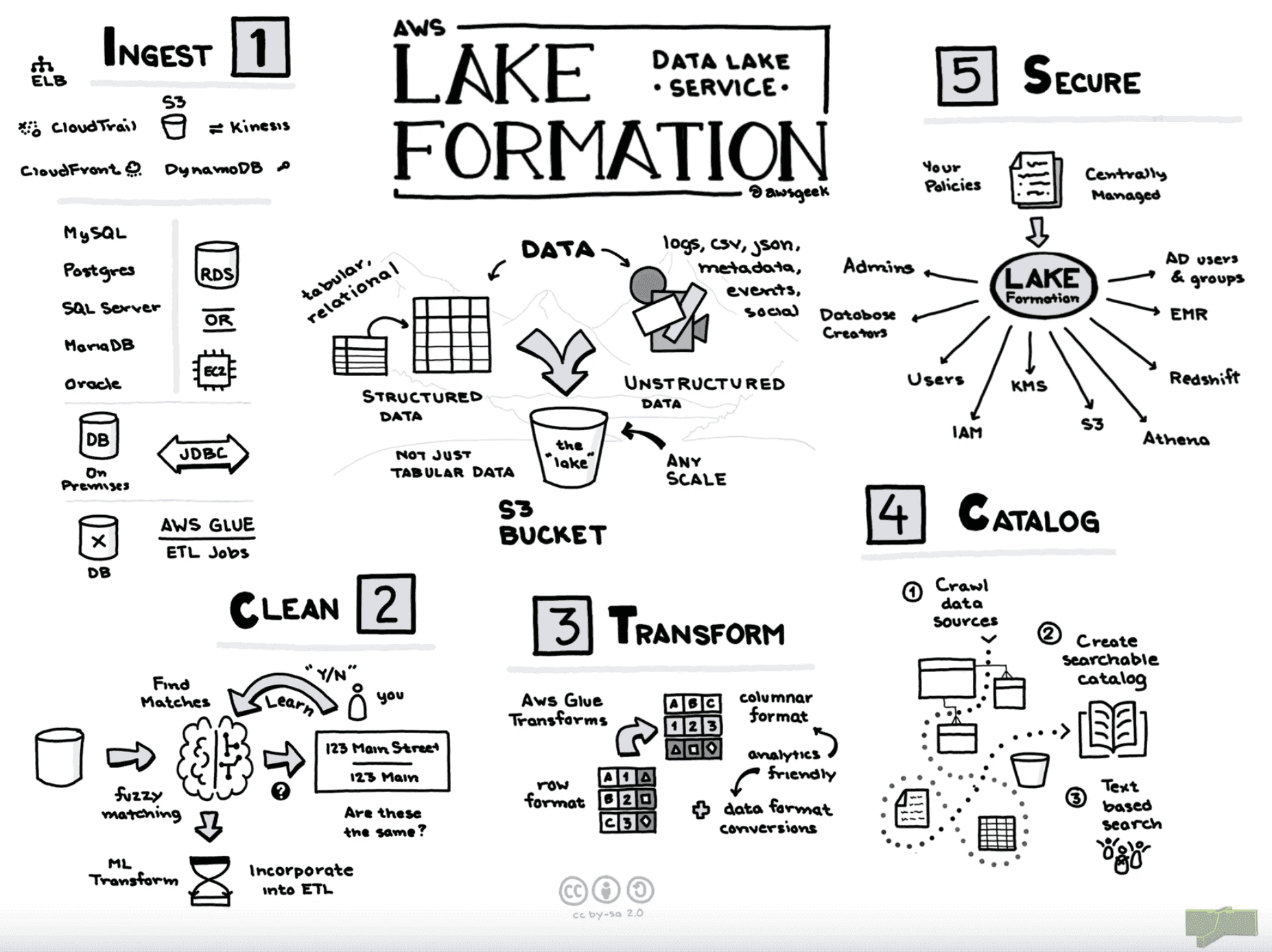
Tutorial: Create a Secure Data Lake with AWS Lake Formation
Rajat Venkatesh — 1/1/2022 — 2 Min Read

AWS Lake Formation helps to build a secure data lake on data in AWS S3. This blog describes the steps to set up a data lake with S3, Glue, Lake Formation, and Athena in AWS. The tutorial will use New York City Taxi and Limousine Commission (TLC) Trip Record Data as the data set.
At the end of the tutorial, you will have a data lake setup with Lake Formation. A future blog will describe how to set up data engineer and data analyst personas.
Prerequisites
Set up AWS Lake Formation using instructions in Getting Started Tutorial.
After the tutorial, the following users and roles are setup:
Administrator is the Administrator IAM User
NycWorkflowRole is the IAM Role for Workflows
lakeadmin is the Data Lake Administrator
Upgrade to Lake Formation Permissions model as described in the Upgrade Tutorial.
Setup AWS Athena
Import Taxi Data into Lake Formation
Allow NycWorkflowRole to read NYC Data
- Goto IAM > Policies > Create Policy
- Follow the wizard and create a policy with the name S3NycBucketRead with the following definition:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::nyc-tlc",
"arn:aws:s3:::nyc-tlc/*"
]
}
]
}
Attach S3NycBucketRead policy to NycWorkFlowRole
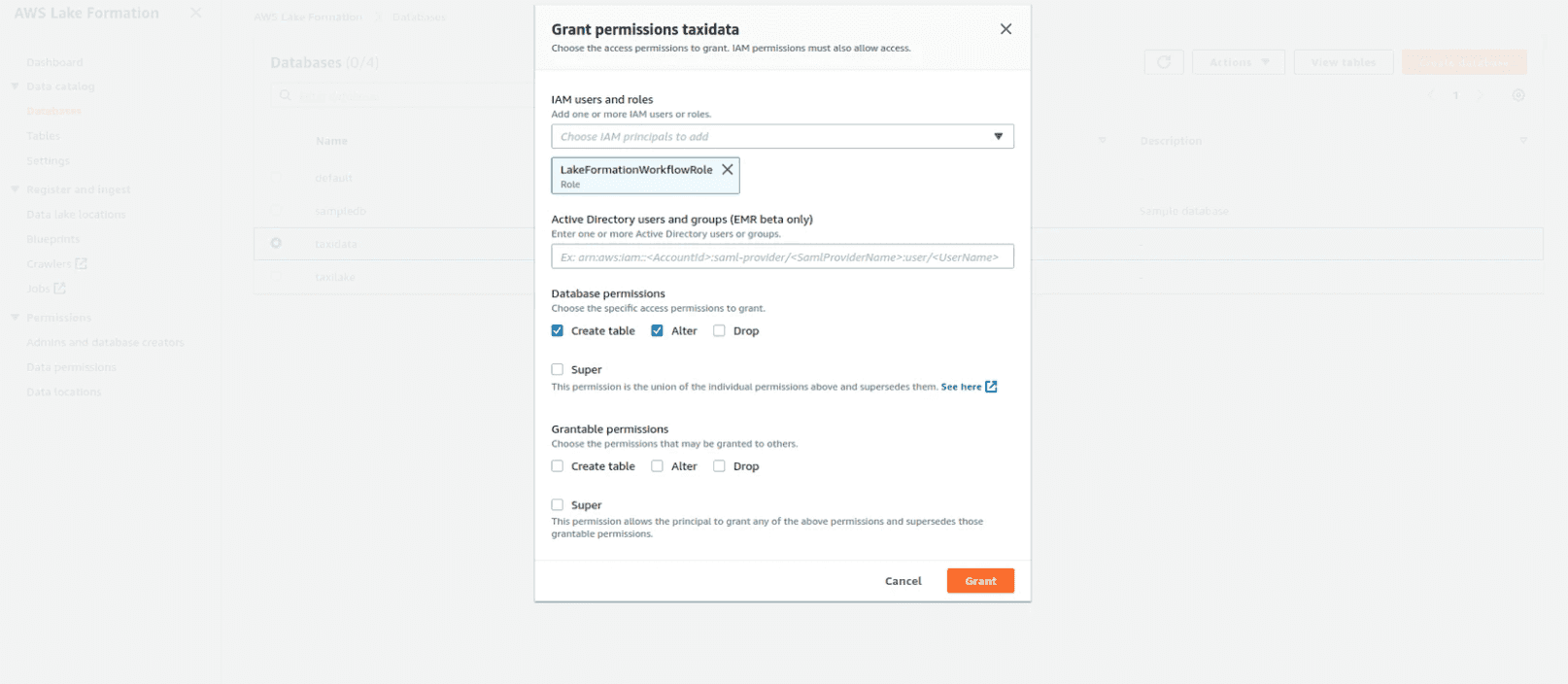
Create a database and grant permissions
- Head to AWS Lake Formation > Databases > Create Database
- Fill out the form with the details below and click on Create Database -Name: taxidata
- Click on Databases in the left navigation pane
- Select taxidata
- Click on Actions > Grant
- Fill up the form with the following details and then click on Grant
- IAM Users and Roles: NycWorkflowRole
- Database Permissions: Create Table, Alter.
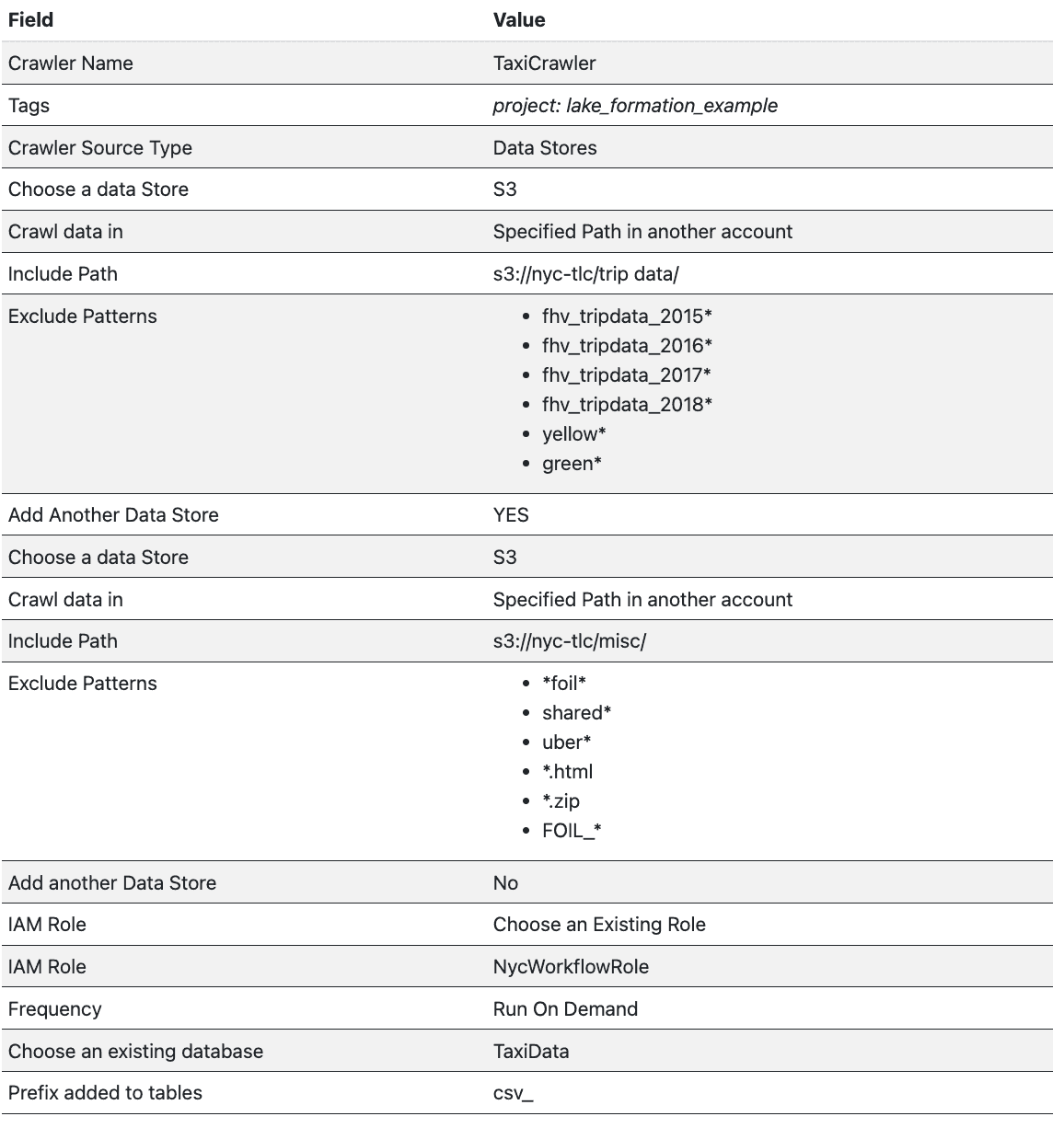
Create a Crawler to register the data in the Glue data catalog
A Glue Crawler will read the files in nyc-tlc bucket and automatically create tables in a database.
Head to AWS Glue > Crawlers > Add Crawler
Fill in the following details in the wizard and click Finish at the end.
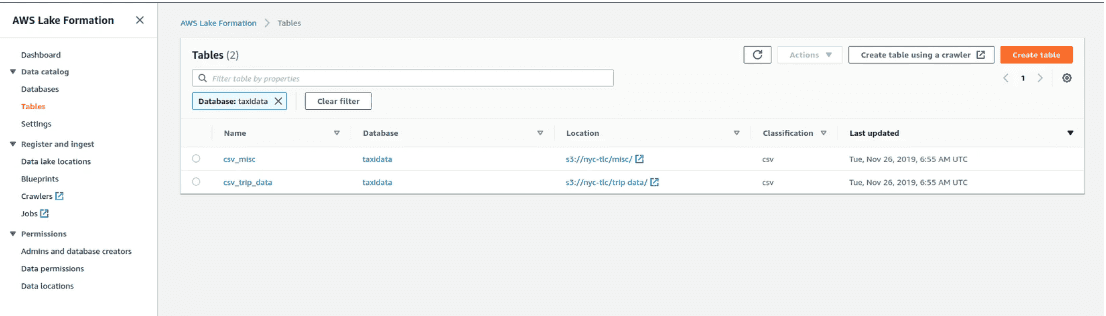
In the crawlers list, select the TaxiCrawler and click the Run Crawler button. This should take less than a minute, and it will crawl the CSV files you've not excluded in the taxi S3 bucket.
Database -> Tables and review the tables.
Verify Data in AWS Athena
Fire up athenacli as lakeadmin and run a couple of queries to verify the data looks good.
us-east-2:default> select * from taxidata.csv_trip_data limit 10;
+----------------------+---------------------+------------------+--------------+--------------+---------+-------------------+
| dispatching_base_num | pickup_datetime | dropoff_datetime | pulocationid | dolocationid | sr_flag | hvfhs_license_num |
+----------------------+---------------------+------------------+--------------+--------------+---------+-------------------+
| B00013 | 2015-01-01 00:30:00 | | <null> | <null> | <null> | <null> |
| B00013 | 2015-01-01 01:22:00 | | <null> | <null> | <null> | <null> |
| B00013 | 2015-01-01 01:23:00 | | <null> | <null> | <null> | <null> |
| B00013 | 2015-01-01 01:44:00 | | <null> | <null> | <null> | <null> |
| B00013 | 2015-01-01 02:00:00 | | <null> | <null> | <null> | <null> |
| B00013 | 2015-01-01 02:00:00 | | <null> | <null> | <null> | <null> |
| B00013 | 2015-01-01 02:00:00 | | <null> | <null> | <null> | <null> |
| B00013 | 2015-01-01 02:50:00 | | <null> | <null> | <null> | <null> |
| B00013 | 2015-01-01 04:45:00 | | <null> | <null> | <null> | <null> |
| B00013 | 2015-01-01 06:30:00 | | <null> | <null> | <null> | <null> |
+----------------------+---------------------+------------------+--------------+--------------+---------+-------------------+
10 rows in set
Time: 4.926s
us-east-2:default> select * from taxidata.csv_misc limit 10;
+------------+-----------------+---------------------------+---------------+
| locationid | borough | zone | service_zone |
+------------+-----------------+---------------------------+---------------+
| 1 | "EWR" | "Newark Airport" | "EWR" |
| 2 | "Queens" | "Jamaica Bay" | "Boro Zone" |
| 3 | "Bronx" | "Allerton/Pelham Gardens" | "Boro Zone" |
| 4 | "Manhattan" | "Alphabet City" | "Yellow Zone" |
| 5 | "Staten Island" | "Arden Heights" | "Boro Zone" |
| 6 | "Staten Island" | "Arrochar/Fort Wadsworth" | "Boro Zone" |
| 7 | "Queens" | "Astoria" | "Boro Zone" |
| 8 | "Queens" | "Astoria Park" | "Boro Zone" |
| 9 | "Queens" | "Auburndale" | "Boro Zone" |
| 10 | "Queens" | "Baisley Park" | "Boro Zone" |
+------------+-----------------+---------------------------+---------------+
10 rows in set
Time: 3.116s
Summary
This tutorial showed how to set up a data lake containing NYC Taxi Trip data using AWS Lake Formation. This data lake is ready to provide secure access to data engineers, analysts, and data scientists. We would love to hear from you if you found this tutorial helpful. Get in touch using the chat widget.
Similar Posts

A Guide on Getting Started with Data Governance
Rajat Venkatesh — 2/17/2022 - 3 Min Read
Get started on building a data governance platform for your organisation with our guest writer, Syed Atif Akhtar.

What are the differences between data catalogs, dictionaries, taxonomies and glossaries?
Rajat Venkatesh — 10/9/2020 - 3 Min Read
Learn which data system you should use, based on who uses the metadata.

Why do we need Data Governance? What are its Challenges?
Rajat Venkatesh — 7/10/2020 - 1 Min Read
The first step is to understand what data governance is. Data Governance is an overloaded term and means different things to different people. It has been helpful to define Data Governance based on the outcomes it is supposed to deliver.
Get in touch for bespoke support for PII Catcher
We can help discover, manage and secure sensitive data in your data warehouse.